



Memory Allocators 101
For the last few weeks, I've been working on a couple of patches to tcmalloc, Google's super high performance memory allocator. I'm going to post about them soon, but first I thought it would be cool to give some background about what a memory allocator actually does. So, if you've ever wondered what happens when you call malloc or free, read on.
A memory allocator's responsibility is to manage free blocks of memory. If you've never read a malloc implementation, you may have assumed that calling free simply causes memory to be released to the operating system. But acquiring memory from the OS has a cost, so allocators tend to keep free chunks around for a while for possible re-use before deciding to release them.
Managing freed memory is an incredibly interesting and hard problem with two main concerns: performance and reducing heap fragmentation / waste:
- How do we organize free blocks of memory such that we can quickly locate a sufficiently large block (or determine that we lack one) when someone calls
mallocwithout making calls tofreeprohibitively expensive? - What can we do to reduce fragmentation and waste in the face of sometimes drastically changing allocation patterns over the lifetime of a (potentially long-running) program? It's worth noting that heap fragmentation can have a substantial impact on CPU cache efficiency.
- As a bonus, there's also the matter of concurrency, but that's probably beyond the scope of this post.
The most fun part of this problem is that our two primary objectives are often in direct opposition. For example, keeping one linked list of free blocks per allocation size (say, rounded up to number of pages) can make calls to malloc best case constant time, but unless some waste is accepted and chunks are kept around long enough to be reused, the worst case path will be taken more often than not.
Of course, there also are a multitude of other issues to consider, such as how to decide to release memory to the operating system, and how to avoid becoming the bottleneck in a concurrent program (I'm looking at you, glibc). And the implementation details are interesting, too.
Implementation
A very basic malloc implementation might use the linux system call sbrk(2) to acquire memory from the operating system and a linked list to store free chunks. That would make calls to free constant time, but malloc would be O(n).
Of course, the allocator needs to store metadata about each chunk it manages, such as its size, free/in-use status, free-list pointer(s), etc. But since you can't exactly call malloc in an allocator, it's common to store metadata in a "header" that just precedes the address that is handed to the application. So, if the header is 16 bytes in size, then the header would start at ptr - 16. Pointer arithmetic galore.
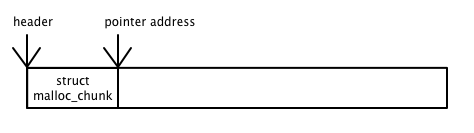
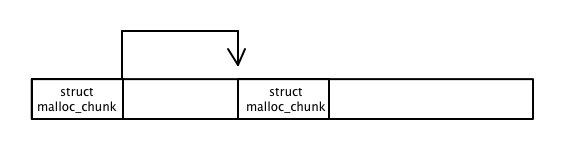
In order to reduce fragmentation and promote memory reuse, it's common for malloc implementations to attempt to coalesce free blocks of memory with adjacent ones, if they happen to also be free. If metadata is being stored in a header, then it's easy to determine the size and status of the pointer to the right.
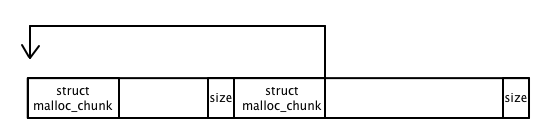
But the header doesn't provide any way of determining the size of the chunk to the left, so coalescing mallocs frequently put the size of each block in a footer, which is typically sized to fit a size_t. Then finding the chunk to the left would look something like this:
Things get even more complicated because subsequent invocations of system calls like sbrk or mmap aren't guaranteed to return contiguous virtual addresses. So, when looking for chunks to coalesce, care has to be taken to make sure that invalid pointers aren't dereferenced by adding to a pointer that's on the edge of what's being managed.
Typically this means creating and maintaining a separate data structure with which to keep track of the regions of virtual address space that the allocator is managing. Some allocators, such as tcmalloc, simply store their metadata in that data structure rather than in headers and footers, which avoids a lot of error-prone pointer arithmetic.
I could probably continue writing about this forever, but this seems like a good place to stop for now. If your interest is piqued and you'd like to learn more about memory allocators, I highly recommend diving in to writing your own malloc implementation. It's a challenging project, but it's fun and it'll give you a lot of insight in to an important part of how your computer works.
Soon I'll follow up on this post with one about the allocator work I've been doing lately. Also, if you're interested in this kind of stuff, check out my new podcast where Joe Damato and I talk about systems programming. We'll definitely be covering allocators in the next few weeks sometime.
Some allocator resources:
- malloc(3) man page
- http://www.cs.cmu.edu/afs/cs/academic/class/15213-f10/www/lectures/17-allocation-basic.pdf
- tcmalloc docs
- glibc malloc source — this is some random github repo, so I have no idea how much its been fucked with